8人限定参加可能短期ハイリターン案件! リスク無し!操作簡単 即日利益反映可能 情報完全配信制!指示あり!爆稼ぎ可能 気になる方、是非LINE追加してください↓ LINEID:mika00a
🌟【限定募集】🌟
リスク0で稼げます🔥 スマホ有れば誰でも稼げる💪🔥
応募が殺到しております、ご興味ある方は 是非お早めに連絡下さい✨ LINEID:mika336
【限定募集】
リスク0で稼げます スマホ有れば誰でも稼げる
応募が殺到しております、ご興味ある方は 是非お早めに連絡下さい LINEID:kyo255361
応募が殺到しております、ご興味ある方は 是非お早めに連絡下さい
LINEID:mika361
従業員と行っています。
クレイジーなやつw
もうChatGPT無しではきついww
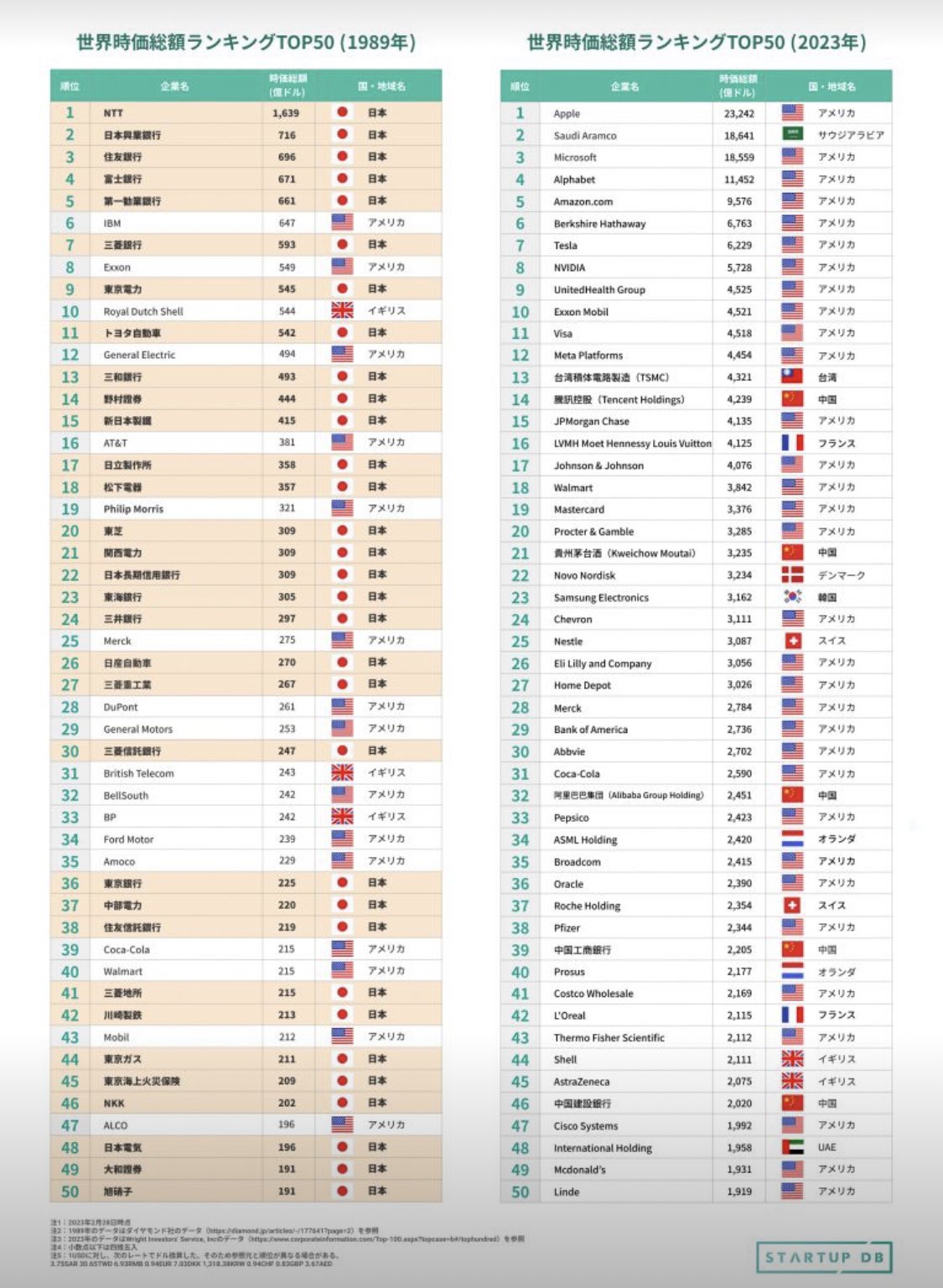
日本はランキングから消えました
1位:中小企業診断士 1029万円 1位:社会保険労務士 1029万円 3位:弁護士 945万円 3位:司法書士 945万円 3位:弁理士 945万円 3位:土地家屋調査士 945万円 7位:税理士 658万円 8位:行政書士 584万円 9位:不動産鑑定士 584万円
【10日以内に稼いでもらいます】 今まで副業で稼いだ事がない人は注目! 100%10日以内で稼がせます!
https://301.run/r/n3lfVHP
英語のみですが登録不要で無料で使えます。 https://pfpmaker.com/
英語版のみですが登録不要で無料で使えます。 https://panzoid.com/
英語版しかないですが無料で写真をキレイにしてくれます。 https://www.restorephotos.io/r
デザイン選び放題です。 英語サイトですが無料で使えます。
https://venngage.com/
英語のみ、無料で使えます。
D-ID Creative Reality™️
無料で使えます。英語サイト https://flair.ai/
日本語対応してます。完全無料でつかえます。
https://www.naturalreaders.com/
ブログ内広告主募集一覧 https://shoucll.cloud-line.com/blog/2023/03/109164/
3Dのマネキンを自由に動かして、好きなポーズで画像を生成できるサイトです。 https://plask.ai
しかもリアルな人だけでなくアニメ画像にも対応
ポーズを決めて、プロンプトを打てば瞬時に画像を作れる
これは画像生成の幅が広がる 無料です❤️
https://fliki.ai/ やり方次第で短時間で動画広告が作れます。 無料で使えます。
詐欺や偽情報、投資勧誘等にご注意ください!サイトへのアクセス及び個人情報ご入力の前に、信用できるサイトかどうか入念なご確認をお願いいたします。ビジネス紹介センターでは匿名で誰でも書込みができるため一切の責任を負いかねますので予めご了承ください。
※掲示板をご利用の際には利用規約をご確認ください。 ※重複する題名の作成はご遠慮ください。 ※私怨による誹謗中傷、援助交際、違法薬物の売買、偽情報、犯罪行為を誘発する書き込みや犯罪行為を誘発する書き込みは禁止です。 ※援助交際、児童ポルノ、薬物売買関連投稿は刑事罰の対象になります。 ※個人または不特定多数の人に対しての攻撃的な書き込みや不快感を与える書き込みについては、見つけ次第削除及び書き込み禁止措置を取らせて頂く場合があります。 ※書込みで発生する全ての責任は投稿者責任になります。 掲示板では節度を持った書き込みのご協力をお願いいたします。